A Benchmarking and Comparative Analysis of Python Libraries for Data Cleaning: Evaluating Accuracy, Processing Efficiency, and Usability Across Diverse Datasets
Keywords:
CleanPy, data cleaning, DataPrep, Pandas, performance evaluation, PyJanitor, usabilityAbstract
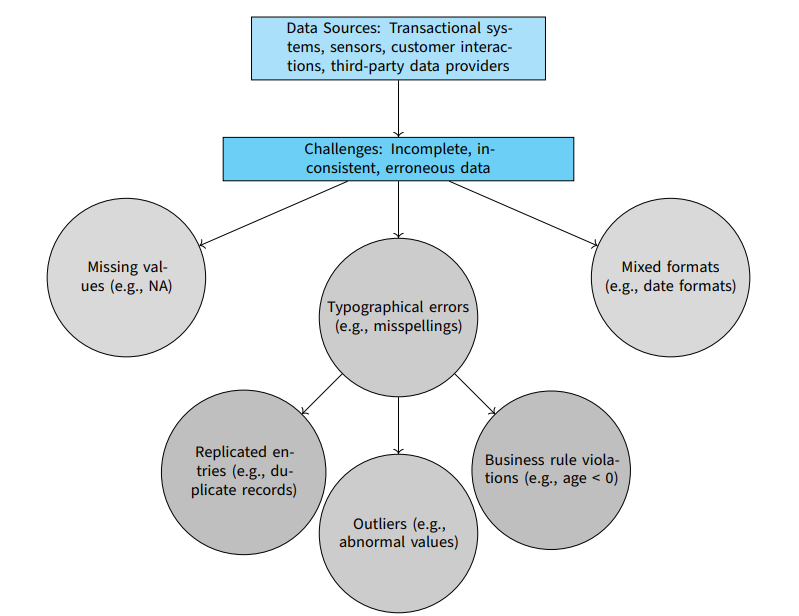
This research evaluates the performance of four Python libraries—Pandas, CleanPy, DataPrep, and PyJanitor—in addressing common data cleaning tasks across diverse datasets. The study focuses on three metrics: data cleaning accuracy, processing efficiency, and ease of use. Four datasets were used, representing different types of data and common quality issues such as missing values, duplicate records, inconsistent formatting, and outliers. These datasets included customer information, sales transactions, sensor data, and financial transactions. Pandas achieved the highest accuracy in tasks such as missing value imputation, duplicate removal, formatting correction, and outlier detection. However, it required more complex coding. CleanPy and DataPrep, while slightly less accurate, provided user-friendly interfaces and required less code, making them effective for routine cleaning tasks. DataPrep also excelled in processing efficiency, often completing tasks faster than the other libraries. PyJanitor, extending Pandas’ functionality, offered a good balance between advanced features and ease of use. The findings highlight the strengths and limitations of each library. Pandas is recommended for users who prioritize accuracy and can handle its complexity. CleanPy and DataPrep are suitable for users needing efficient and straightforward solutions with minimal coding. PyJanitor is ideal for those seeking enhanced capabilities without the full complexity of Pandas. This research aids data practitioners in selecting the most appropriate tool for their data cleaning needs, enhancing the accuracy and efficiency of data preparation.